一种基于Bi-LSTM-CNN的分词方法与流程
本发明属于计算机软件技术领域,涉及一种基于bi-lstm-cnn的分词方法。
背景技术:
自然语言处理问题中亚洲类型的文字并非像西文具有天然的空格分隔符,很多西文处理方法并不能直接用于亚洲类型(中文、韩文和日文)文字的处理,这是因为亚洲类型(中文、韩文和日文)必须经过分词的这道工序才能保持和西文一致。因此,分词在亚洲类型文字的处理中是信息处理的基础,其应用场景包括:
1.搜索引擎:搜索引擎中一个重要的功能就是做文档的全文索引,其内容是将文字进行分词,然后将文档的分词结果和文档形成一个倒排索引,用户在查询的时候也是先将查询的输入语句进行分词,而后将分词的结果和索引数据库进行对比,从而找出与当前输入最为相似的文档。
2.自动摘要生成:自动摘要是指将一篇较长的文档用一段较短的语言文字去总结。而在总结的过程中,就需要计算一篇文档中关键词,因此在计算关键词之前必须先对文档做分词处理。
3.自动校对:自动校对是指对一段文字作语法错误的检查,其检查的粒度还是基于词的方式做的检查,因此需要将用户输入的连续文字做分词处理。
传统的分词方法可以分为基于词典的分词,基于词频统计的方法以及基于知识的方法;基于词典的分词严重依赖于词典库,词频统计的hmm(隐马尔可夫)和crf(条件随机场)其只能关联当前词的前一个词的语义。基于知识的人工神经网络模型因模型训练时的梯度消失问题,在实际的应用中网络层数少,最终分词结果优势不明显。
基于词典的分词方法严重依赖于词典库,效率比较低,且不能够识别未登录词;本发明中登录词指的是已经出现在语料词表中的词,未登录词指的是没有出现在语料词表中的词。
基于词频统计分词方法(例如n-gram),其只能关联当前词的前n-1个词的语义,识别精度不够高,当n增加的时,效率非常低。而且对未登录的识别率偏低。
技术实现要素:
针对现有技术中存在的技术问题,本发明的目的在于提供一种基于bi-lstm-cnn的分词方法。本发明通过自然语言处理中的序列标注(sequentiallabeling)将一个序列作为输入,并训练一个模型使其为每一序列片段数据产生正确的输出。
针对与中文类似(英文天然带有空格作为词之间的分割符)的语言进行分词的方法。本发明要解决的核心问题包含三个:1分词的效率,2分词的精度,3未登录词的识别精度。
本发明的技术方案为:
一种基于bi-lstm-cnn的分词方法,其步骤包括:
1)将训练语料数据orgdata转化为字符级的语料数据newdata;
2)统计该语料数据newdata字符得到一字符集合charset,并对该字符集合charset中每个字符进行编号,得到该字符集合charset对应的字符编号集合charid;统计newdata中的字符的标签,得到一标签集合labelset,对该标签集合labelset的标签进行编号,得到对应的标签编号集合labelid;
3)将newdata按照句子长度划分,得到若干句子;然后根据句子长度对得到的句子进行分组,得到包括n组句子的数据集合groupdata;
4)随机无放回的从该数据集合groupdata中选取一句子分组,从该句子分组中抽取batchsize个句子,每一个句子的字符构成一数据w,该句子的字符对应的标签集合为y;根据字符编号集合charid将数据w转换为对应的编号,得到数据batchdata;根据标签编号集合labelid将集合y中的标签转换为对应的编号,得到数据yid;
5)将步骤4)生成的多个数据batchdata及其对应的标签数据yid一起送入深度学习模型bi-lstm-cnn,训练该深度学习模型bi-lstm-cnn的参数,当深度学习模型产生的损失值cost(y′,yid)满足设定条件或者达到最大迭代次数n,则终止深度学习模型的训练,得到训练后的深度学习模型bi-lstm-cnn;否则采用步骤4)的方法重新生成数据batchdata训练该深度学习模型bi-lstm-cnn;
6)将待预测的数据predata转换成与该深度学习模型bi-lstm-cnn匹配的数据premdata,并将其送入训练好的深度学习模型bi-lstm-cnn,得到分词结果orgresult。
进一步的,该数据batchdata的长度为一固定长度maxlen,当抽取到的数据句子长度l<maxlen时,将该句子后面补maxlen-l个0,得到batchdata;并将对应的数据yid后面补maxlen-l个0,得到数据yid;其中,maxlen等于该深度学习模型bi-lstm-cnn中的bi-lstm层正向的lstm单元个数。
进一步的,产生该损失值cost(y′,yid)的方法为:
31)将数据batchdata在深度学习模型bi-lstm-cnn的embedding层进行向量化,将数
据batchdata中的每个字符转换成一向量;
32)将各数据batchdata对应的向量传入深度学习模型bi-lstm-cnn的bi-lstm层,其中该数据batchdata中的每一字符对应的向量分别传入bi-lstm层正向和反向的一lstm单元;且正向的第i-1个lstm单元的输出结果输入正向的第i个lstm单元、反向的第i-1个lstm单元的输出结果输入反向的第i个lstm单元;
33)将正向和反向的每个lstm单元的输出和
传入concatenate层,即将正向和反向的lstm单元的输出结果拼接在一起组合成hi;
33)将concatenate层的输出hi传入深度学习模型bi-lstm-cnn的第一dropout层;
34)将第一dropout层的输出传入conv卷积层进行卷积后,使用relu激活函数将卷积层的输出设为ci;
35)将该conv层的输出ci依次经第二dropout层、softmax层处理后,将得到的输出y′与传入的数据yid一起计算产生损失值cost(y′,yid)。
进一步的,所述损失值cost(y′,yid)=-yidlog(y′)+(1-yid)log(1-y′);其中y′表示数据batchdata经过该softmax层后的输出。
进一步的,所述设定条件为当前计算的损失值cost(y′,yid)与前m次损失值的平均值的差小于阈值θ。
进一步的,所述步骤2)中,将|li-lj|<δ的句子归入一组;其中,li表示第i句话的句子长度、lj表示第j句话的句子长度,δ表示句子长度间隔。
进一步的,所述步骤1)中,采用bmes的标记方式将该训练语料数据orgdata中的带有标签的每个词语按照字符级切分,将位于词语最开始的字符标记为b,位于词语中间的字符标记为m,位于词语末尾的字符标记为e,如果词语只有一个字符则标记为s。
进一步的,使用adam梯度下降算法训练该深度学习模型bi-lstm-cnn的参数。
本发明分两个阶段:训练阶段,预测阶段。
(一)训练阶段:(参考图1的左边虚线框)
步骤1:将带有标签的训练语料数据转换为字符级的语料数据。
步骤2:使用adam梯度下降算法训练深度学习模型。
(二)预测阶段:(参考图1的右边虚线框)
步骤1:将没有标签的测试语料数据转换为字符级的语料数据。
步骤2:使用训练阶段训练好的深度学习模型进行预测。
本发明主要具有以下优点:
为了解决未登录词问题,本发明放弃了传统的词表方法,而是采用基于词向量的思想,而且是基于字符的向量,而不是词语。传统的基于词表的方法,只有出现在词表中的词语才能够识别;没有出现在词表的词,也就是未登录词,就不能识别。每个词都是由一个个的字符组成的,采用基于词向量的思想,那么只要出现在字符表里面的所以字符构成的词语都能够识别。这里提到的字符,如果是处理中文的话,可以理解成就是所有汉字字符以及汉字标点符号的集合。
为了解决传统分词方法精度低的问题,本发明采用深度学习的思想,利用双向长短期记忆神经网络模型(bi-lstm)和卷积神经网络(cnn)模型相结合。
为了解决传统分词效率低,避开词频统计,避开字符串匹配,而是采用类似函数映射的方式进行分词。
本发明基于bi-lstm-cnn的分词方法,采用字符级而不是词语级,可以规避未登录词的问题;另外采用双向长短期记忆神经网络bi-lstm和卷积神经网络cnn的组合模型相比传统的算法,精度提高了很多。
附图说明
图1为本发明方法流程图。
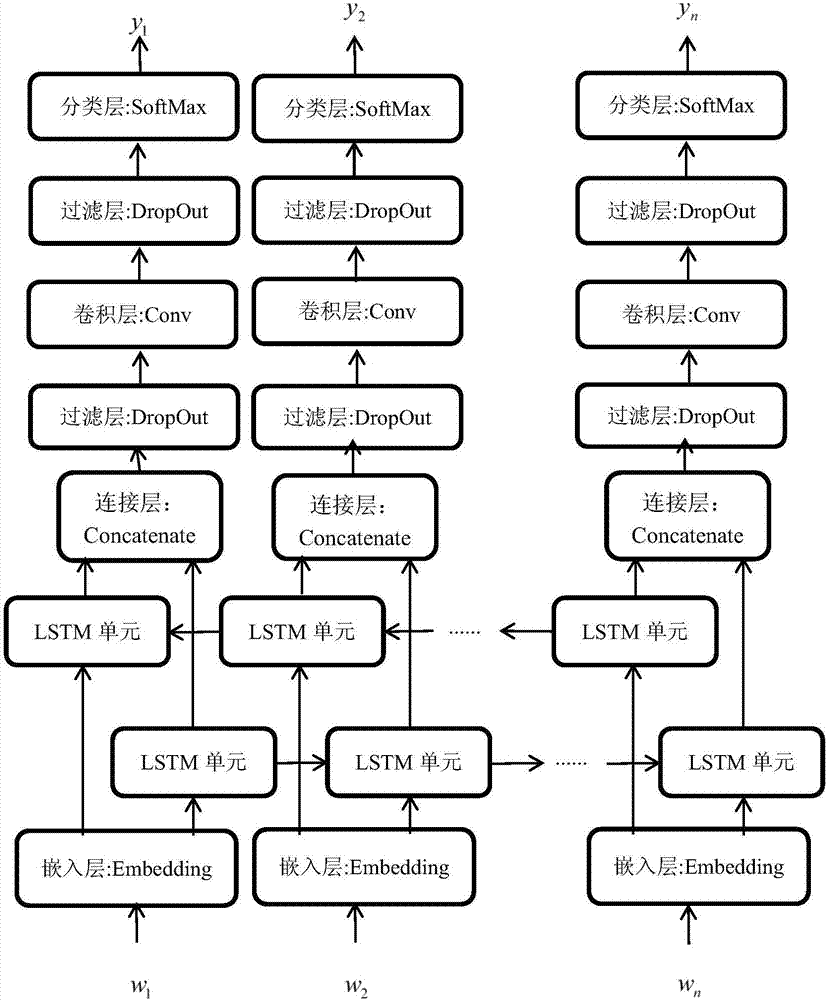
图2为深度学习模型架构图。
具体实施方式
为使本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附图作详细说明如下。
本发明的方法流程如图1所示,其包括:
(一)训练阶段:
步骤1:将原始训练语料数据orgdata转化为字符级的语料数据newdata。具体为:采用bmes(begin,middle,end,single)的标记方式,将原始训练语料数据中的带有标签的每个词语按照字符级切分。则位于该词语最开始的字符标记为b,位于该词语中间的字符标记为m,位于该词语末尾的字符标记为e,如果该词语只有一个字符则标记为s。
步骤2:统计newdata中的字符,得到一字符集合charset,例如,假设有两个词语为:中华,中国,合并之后的字符集合就为:{中,华,国}。将该字符集合charset中每个字符按照自然数增序编号,得到字符集合charset对应的字符编号集合charid。统计newdata中的字符的标签,得到一标签集合labelset,也一样将其产生对应的标签编号集合labelid。标签集合labelset一般为{b,m,e,s},产生对应的labelid,即将标签集合labelset中的这些字符转成一个数字来代表,便于程序识别。
步骤3:将newdata按照句子长度划分。设li表示第i句话的句子长度,则将|li-lj|<δ的句子归入一组,其中δ表示句子长度间隔。设分组之后的数据为groupdata,一共设为n组。
步骤4:随机无放回的从groupdata的某组句子中抽取batchsize句,每一句子的字符构成数据w,该句子的字符对应的标签集合为y,并将抽取的数据w通过charid转换为对应的编号,得到固定长度的数据batchdata(对应于图2中的w1,w2,…,wn),以及把对应的标签y通过labelid转换为对应的编号,得到固定长度的数据yid。因为同一组的句子长度接近,相比乱抽取而言,精度提高大约2个百分点。
步骤5:将步骤4的多个数据batchdata及其对应的标签数据yid一起送入深度学习模型,产生损失值cost(y′,yid)。具体的计算公式如下:
cost(y′,yid)=-yidlog(y′)+(1-yid)log(1-y′)(公式1)
其中y′表示batchdata经过深度学习模型分类层(softmax层)后的输出。对应于图2中的y1,y2,…,yn。
步骤6:使用adam梯度下降算法训练深度学习模型的参数。
步骤7:如果深度学习模型产生的cost(y′,yid)计算得到的损失值不再降低,或者达到最大迭代次数n,则终止深度学习模型的训练;否则跳到步骤4。
其中,costi′(y′,yid)表示前i次迭代时的损失值,cost(y′,yid)表示当前迭代产生的损失值,这个公式表达的意思是如果当前的损失值与前m次损失值的平均值的差小于阈值θ,则认为不再降低。
预测阶段:
步骤1:将待预测的数据predata转换成与模型匹配的数据格式premdata。具体为:将待预测的数据转换成字符级的数字数据。
步骤2:将premdata送入训练阶段训练好的深度学习模型,并得到分词预测结果orgresult。
训练阶段步骤4所述的:将抽取的数据通过charid转换为若干个固定长度的数据batchdata,以及把对应的标签通过labelid转换为若干个固定长度的数据yid。具体为:
步骤1:将抽取到的数据w转换成数字,也即通过charset与charid的对应关系,将w中的每个字符转换成对应的数字。
步骤2:将抽取的数据w对应的标签集合y转换成数字,也即通过labelset与labelid的对应关系,将y中的每个字符转换成对应的数字,得到数据yid。
步骤3:假设规定长度为maxlen,当抽取到的数据句子长度l<maxlen时,将句子后面补maxlen-l个0,得到batchdata;maxlen等于bi-lstm层正向的lstm单元个数;因为通常只有不到5%的句子长度非常长,如果过分在意那些长的句子的话,那么精度会降低不少(如果出现l≥maxlen的情况,简单的处理方式是直接丢掉,或者将长句子分割成短句子进行处理)。并将w对应的数据yid后面补maxlen-l个0,得到yid。
本发明的深度学习模型架构图如图2所示,训练阶段步骤5所述的:将数据batchdata及其标签数据yid送入深度学习模型,产生损失值cost(y′,yid),具体为:
步骤1:将传入的数据batchdata在embedding层进行向量化,也即将每一数据batchdata中的每个字符都通过一字符转向量的向量表char2vec转换成字符id编号对应的向量。向量表char2vec中每个字符有一个对应的字符id编号。
步骤2:将步骤1得到的向量传入bi-lstm层,详细为:将每条数据batchdata中的第一个字符对应的向量w1传入bi-lstm层正向的第一个lstm单元,第二个字符对应的向量w2传入bi-lstm层正向的第二个lstm单元,依次类推;同时正向的第i个lstm单元的输入除了每条数据中的第i个字符对应的向量外,还包含正向的第i-1个lstm单元的输出,即正向的第i-1个lstm单元的输出结果输入正向的第i个lstm单元。每条数据batchdata中的第一个字符对应的向量传入bi-lstm层反向的第一个lstm单元,第二个字符对应的向量传入bi-lstm层反向的第二个lstm单元,依次类推;同时反向的第i个lstm单元的输入除了每条数据中的第i个字符对应的向量外,还包含反向的第i-1个lstm单元的输出,即反向的第i-1个lstm单元的输出结果输入反向的第i个lstm单元注意,每个lstm单元一次接收到的向量并不是只有一个,而是batchsize个。
步骤3:将正向和反向的每个lstm单元的输出和
传入concatenate层,也即是将正向和反向的lstm单元的输出结果拼接在一起组合成
步骤4:将concatenate层的输出传入dropout层,也即是随机的将hi中η(0≤η≤1)的数据隐藏掉,不让其继续向后传递。
步骤5:将dropout的输出传入conv卷积层进行卷积后,使用relu激活函数将卷积层的输出设为ci。
步骤6:与步骤4类似,将conv层的输出ci传入dropout层,也即是随机的将ci中η(0≤η≤1)的数据隐藏掉,不让其继续向后传递。
步骤7:将dropout的输出传入softmax层,并将softmax的输出y′与传入的相应标签数据yid产生最终的损失值cost(y′,yid),具体的计算见公式1。
预测阶段步骤2所述的深度学习模型,即为训练阶段训练好的深度学习模型,不过在预测时,其中涉及到的dropout层的参数η=1,表示不隐藏任何数据,全部都传递到下一层。
以上实施仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。
- 还没有人留言评论。精彩留言会获得点赞!